NLP Tokenization: Types, Examples, and How It Powers AI Models
AI works with huge amounts of text every day. This text appears in chats, reviews, emails, documents, search queries, and support tickets. Machines cannot read this text as humans do. They need a clean structure before they can find meaning.
NLP helps machines process human language. It prepares text so models can analyze patterns and user intent. NLP tokenization is one of the first steps in this process. It breaks text into smaller units called tokens. These tokens can be words, sentences, characters, or subwords.
A sentence can become separate words. A long paragraph can become separate sentences. This gives the model smaller parts to understand. It also helps the system convert text into a format that algorithms can use.
Tokenization may look simple at first. It plays a major role in automation and modern AI applications. This blog explains how it works and why it matters for AI-based text processing.
What Is NLP Tokenization?
NLP tokenization breaks text into smaller language units so a machine can process it with better clarity. These units are called tokens. A token can be a word, a sentence, a character, or a subword. This process helps language models turn raw text into structured input.
How It Works
A user may type a sentence into a chatbot or search tool. The system does not process the full sentence at once. It first breaks the text into smaller parts. Each part helps the model understand context and user intent. This makes tokenization an important step in natural language processing. Every language model needs clean text before it can analyze or respond to human input.
For example, a sentence like “AI improves customer support” can be split into separate words. Each word becomes a token. The model then studies these tokens to understand the message. This process supports search tools, chatbots, translation systems, and content analysis platforms.
Why It Matters
To understand what is tokenization in NLP, it helps to see it as the first step in text preparation. It reduces text complexity and supports search tools for content analysis platforms.
Tokenization in NLP also helps prepare text for deeper language tasks. These tasks include pattern detection and response generation.
Turn assets into digital opportunities. —launch your tokenization platform today
Schedule a CallHow Tokenization Changes Across Technologies
Tokenization is not limited to one field. Its meaning changes with the system that uses it. In language models, it prepares text for analysis. In blockchain, it creates digital units for assets or value.
NLP tokenization focuses on text. It breaks a sentence or paragraph into smaller units. These units help a model read patterns and understand context. This makes raw text easier to process inside search tools and document systems.
Blockchain uses tokenization for a different purpose. It turns assets into digital units that can be stored and managed on a secure platform. The asset can be property ownership, investment value, or another real world asset. This is why businesses exploring property digital systems often look at real estate tokenization platform development to build secure asset platforms.
Both uses share one idea. Tokenization turns complex information into smaller units that systems can manage. The difference lies in what gets divided and why it matters.
How NLP Tokenization Works Step by Step
Tokenization starts when a system receives text. The text can come from a chatbot message. It can come from a search query. It can also come from a document review comment or support ticket. The system treats this text as raw input.
1. Text Input
The first step is text collection. A model needs a sentence or a full document before it can process language. At this stage, the text still has spaces and different word forms. It may also include spelling mistakes or informal language.
2. Text Cleaning
The next step prepares the text for better processing. The system may remove extra spaces. It may handle punctuation. It may convert text into a consistent format. Clean text helps the model avoid confusion during analysis.
3. Text Splitting
After cleaning, the text gets split into smaller units. This is the core step in tokenization in NLP. A sentence can break into words. A paragraph can break into sentences. A complex word can break into smaller parts. The method depends on the model and the task.
4. Token Creation
Each smaller unit becomes a token. The system then gives each token a structure that a model can read. This helps the model understand how each part connects with the full message. It also makes large text easier to manage.
5. Model Processing
The tokens then move into the language model. The model studies them to identify the meaning and context. It can classify text, answer questions, translate language, or support chatbot replies.
Different NLP tokenization techniques work better for different tasks. A search tool may use word level tokens. A large language model may use subword tokens. A spelling correction tool may need character level tokens. The right method improves accuracy and helps the system understand text with more depth.
Different Tokenization Methods Used in NLP and AI Development
The main types of tokenization in NLP help models handle text at different levels. Some methods focus on full words. Some focus on sentence flow. Others break text into smaller parts. The right method depends on the task language and model.
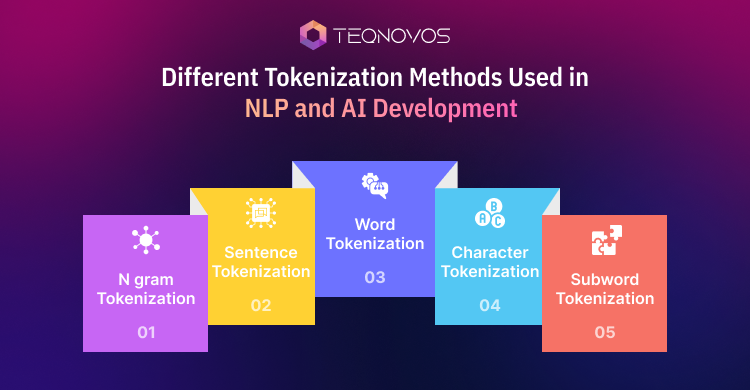
1. Word Tokenization
Word tokenization breaks text into separate words. It helps a model study each word as a separate unit. This method is common in basic text analysis.
For example, the sentence AI improves customer support can turn into word based tokens such as AI, improves, customer, and support.
This method works well for search systems and topic detection. It also works for sentiment analysis and chatbot responses. This helps the model find important words inside large text data.
The main challenge is punctuation and word forms. A system must decide how to treat words like don’t or customer’s. Clean text makes this method more accurate.
2. N gram Tokenization
N gram tokenization groups nearby words or characters together. It helps a model understand context beyond one word. This method works well when the meaning depends on word combinations.
For example, the phrase customer support chatbot can create phrase tokens such as customer support, support chatbot, and customer support chatbot.
This method works well for search ranking and text classification. It also helps with content matching and sentiment analysis. This helps the model find common phrases inside large text data.
The main challenge is token volume. Longer groups create more tokens. This can increase processing needs and make the system heavier.
3. Sentence Tokenization
Sentence tokenization breaks a paragraph into separate sentences. It helps a model understand where one thought ends and another begins. This method is useful for long texts.
For example, the text AI improves support. Chatbots answer faster. This can be split into two sentence level tokens. One token holds the first sentence. The second token holds the next sentence.
This method works well for summaries, document review, legal text analysis, and customer feedback analysis. It helps the model study each sentence before it reviews the full text.
The main challenge is sentence boundary detection. A full stop does not always end a sentence. Good tokenizers check context before splitting the text.
4. Character Tokenization
Character tokenization breaks text into single characters. Each letter, number, or symbol becomes a token. This method gives the model a deeper view of the text.
For example, the word chat can become character based tokens for each letter in the word.
This method works well for spelling correction and text generation. It also assists in rare word handling and language tasks with unclear word boundaries. This helps the model process words it has not seen before.
The main challenge is length. A short sentence can create many tokens. This can slow processing and increase model workload.
5. Subword Tokenization
Subword tokenization breaks words into smaller parts. It helps models handle rare words, new terms, and long technical words. This method is common in modern language systems.
For example, the word unhelpful can be split into smaller meaningful parts so the model can understand the word even when it has not seen the full form before.
This method works well for chatbot translation tools, search systems, and large language models. It helps the model understand part of a word even when the full word is new.
The main challenge is balance. Very small parts can reduce meaning. Very large parts can miss new terms. A good tokenizer chooses a level that supports accuracy and speed.
The Role of Tokenization in AI Model Performance
AI models need structured text before they can understand user input. Raw text often has long sentences and mixed formats with unclear patterns. A model cannot process this well without breaking it into smaller parts first.
1. Clear Reading
NLP tokenization gives the model a cleaner way to read text. It turns a message into smaller units that the system can study. These units help the model detect meaning, context, and intent. This makes language analysis more accurate.
2. Chatbot Accuracy
Tokenization supports chatbot accuracy. A chatbot receives questions in many forms. Users may write short queries, long questions, or casual messages. Tokens help the chatbot identify important words and match them with the right response.
3. Search Relevance
Search tools also depend on tokenization. A search system breaks a query into useful terms. It then compares those terms with indexed content. This helps the system return better results. It also improves content matching inside search platforms.
4. Text Classification
Text classification becomes easier with tokens. A model can sort emails and documents into the right categories. It can also detect sentiment in customer feedback. This helps businesses understand user opinions and improve service decisions.
5. Document Processing
Document processing gains value through tokenization. Large files become easier to scan and analyze. A model can find names, dates, topics, issues, and repeated patterns inside the text. This helps teams reduce manual review work.
6. AI Workflows
Businesses that build systems for text analysis automation and customer support often need strong language processing workflows. This is where AI software development services help create systems that process text and support smarter digital operations.
Tokenization is not just a technical step. It shapes how well an AI model understands language. Better tokenization can lead to better responses and more useful business insights.
Common Issues That Affect Tokenization in AI Models
Tokenization looks simple when the text is clean. Real user text is rarely clean. It often includes errors and mixed languages. These issues make token splitting harder for AI systems.
1. Punctuation Issues
Punctuation can change how a sentence should be split. A full stop may end a sentence. It may also appear in names or abbreviations. A tokenizer must understand the context before it separates text. Poor handling can break meaning and reduce model accuracy.
2. Slang Usage
Users often write in casual language. They use short words and informal phrases. This creates a challenge for NLP tokenization techniques because the system must process language that does not follow standard grammar. Slang can also change by region and audience.
3. Spelling Errors
Spelling mistakes can confuse tokenizers. A misspelled word may become an unknown token. This can affect search results and text classification. Good systems often combine tokenization with spelling correction and text cleaning.
4. Compound Words
Compound words can be difficult to split. Some words carry meaning as one unit. Others make more sense when divided into smaller parts. The system must decide the right split based on the language task.
5. Multilingual Text
Many users mix languages in the same message. This is common in chat reviews and support tickets. Different languages follow different word patterns. Some languages do not use spaces like English. This makes tokenization more complex.
6. Model Accuracy
Different types of tokenization in NLP handle these challenges in different ways. Word methods may fail with rare terms. Character methods may create too many tokens. Subword methods often give a better balance. The right choice depends on the text quality and business use case.
Create trusted digital asset platforms. —start tokenizing real world assets
Schedule a CallCommon Libraries Used for Text Tokenization
Several tools help developers apply tokenization inside language systems. The right tool depends on the project size, model type, data format, and accuracy needs. Some tools work well for learning and testing. Others support production grade AI systems.
1. NLTK
NLTK is often used for basic text processing tasks. It supports word and sentence tokenization. It also helps teams test simple tokenization examples in NLP before they move to larger model workflows. Official NLTK docs describe tokenizers as tools that divide strings into smaller substrings.
2. spaCy
spaCy works well for faster text processing. Its tokenizer segments text into words, punctuation, and other units. It also creates structured text objects that can move through the full language pipeline. This makes it useful for business systems that need cleaner text analysis.
3. Hugging Face
Hugging Face offers tokenizers that support modern model workflows. These tokenizers help prepare text for transformer systems. They also support subword methods that help models handle rare words and new terms. Businesses building advanced language systems can explore a large language model development company for stronger model design and token processing needs.
4. TensorFlow Text
TensorFlow Text supports tokenization inside machine learning pipelines. It offers several options for handling text before model training and prediction. This helps teams keep text processing more consistent across development and deployment.
How Companies Use Tokenization for Smarter Text Processing
NLP tokenization supports many business systems that work with text. It helps companies turn unstructured messages and queries into usable data. This makes AI workflows more accurate and easier to scale.

1. Customer Support
Support teams handle large volumes of customer messages every day. Tokenization helps systems break each message into useful parts. The system can detect key terms’ intent and urgency. This helps route tickets to the right team. It also helps support tools suggest faster replies.
2. Document Review
Many businesses manage policies and internal files. Tokenization helps AI systems scan these documents with more control. The system can identify names and repeated issues. This reduces manual review work and helps teams find important details faster.
3. Search Systems
Search platforms use tokenization to understand user queries. A search tool breaks a query into meaningful terms. It then matches those terms with the right content. This improves the quality. It also helps users find answers or documents with less effort.
4. Content Analysis
Marketing and product teams often study review comments and social content. Tokenization helps systems group words and phrases into patterns. This can reveal customer sentiment and topic trends. The insights help teams improve content strategy and user experience.
5. AI Chatbots
Chatbots rely on tokenization to understand user messages. A chatbot must read short questions and casual language. Tokens help the system detect intent and choose the right response. Businesses building smart conversational tools can work with an AI chatbot development company to create better language support systems.
6. Business Value
Tokenization improves the way AI systems read and process text. It helps teams automate and improve decision making. Strong tokenization also helps businesses build more reliable text analysis workflows across customer support and chatbot systems.
Conclusion
NLP tokenization gives AI systems a clear way to process human language. It breaks raw text into smaller units that models can read and analyze with better accuracy. This step supports many language tasks, such as chatbot replies and content classification.
The right tokenization method depends on the text type and business goal. Word-based methods work well for simple text tasks. Subword methods support modern language models and complex terms. Character-based methods help with rare words and spelling issues.
Tokenization may seem like a small step. It has a strong impact on how well AI systems understand the meaning and intent. Businesses that use language automation need strong text processing workflows to get better results from AI tools.
Book a free consultation with us to build your business value today. Connect with Teqnovos and get started!